Can you explain the different RAID levels and their pros and cons? What are the benefits of using more than the minimum drives -- is it additional capacity, more drive loss, fault tolerance? Under what circumstances can RAID types, specifically RAID 10, survive multiple simultaneous drive failures? Can you also provide some tips for the rebuild process for failed drives in RAID 10?
We use cookies and other similar technologies (Cookies) to enhance your experience and to provide you with relevant content and ads. By using our website, you are agreeing to the use of Cookies. You can change your settings at any time. Cookie Policy.X

ALPHASPIRIT - FOTOLIA
ALPHASPIRIT - FOTOLIA
Q
RAID levels and benefits explained
4
RAID can enable better storage performance and higher availability, and there are many different RAID types. Read about the different levels of RAID and where they work best.
Erin Sullivan and Christopher Poelker
Editor's Note: This content was expanded and updated in October 2017.
Can you explain the different RAID levels and their pros and cons? What are the benefits of using more than the minimum drives -- is it additional capacity, more drive loss, fault tolerance? Under what circumstances can RAID types, specifically RAID 10, survive multiple simultaneous drive failures? Can you also provide some tips for the rebuild process for failed drives in RAID 10?
RAID used to stand for redundant array of inexpensive disks. Today, the term has been updated to redundant array of independent disks.
RAID is a way of grouping individual physical drives together to form one bigger drive called a RAID set. The RAID set represents all the smaller physical drives as one logical disk to your server. The logical disk is called a logical unit number, or LUN.
Using RAID has two main advantages: better performance and higher availability, which means it goes faster and breaks down less often.
Benefits of RAID
The primary benefits of using RAID are performance improvements, resiliency and low costs. Performance is increasedbecause the server has more spindles to read from or write to when data is accessed from a drive. Availability and resiliency are increased because the RAID controller can recreate lost data from parity information.
Parity is basically a checksum of the data that was written to the disks, which gets written along with the original data. RAID can be done in software on a host, such as Windows FTDISK volumes, or in hardware on the storage controllers. The server accessing the data on a hardware-based RAID set never knows that one of the drives in the RAID set went bad. The controller recreates the data that was lost when the drive goes bad by using the parity information stored on the surviving disks in the RAID set.
Standard vs. nonstandard RAID levels
The expansive number of RAID levels can be broken into three categories: standard, nonstandard and nested. Standard levels of RAID are made up of the basic types of RAID numbered 0 through 6.
A nonstandard RAID level is set to the standards of a particular company or open source project. Nonstandard RAID includes RAID 7, adaptive RAID, RAID S and Linux md RAID 10.
Nested RAID refers to combinations of RAID levels, such as RAID 01 (RAID 0+1), RAID 03 (RAID 0+3) and RAID 50 (RAID 5+0).
RAID levels explained
The RAID level you should use depends on the type of application you are running on your server. RAID 0 is the fastest, RAID 1 is the most reliable and RAID 5 is a good combination of both. The best RAID for your organization may depend on the level of redundancy you're looking for, the length of your retention period, the number of disks you're working with and the importance you place on data protection versus performance optimization.

Below is a description of the different RAID levels that are most commonly used in SAN storage arrays. Not all storage array vendors support all the various RAID types, so be sure to check with your vendor for the types of RAID that are available with their storage.
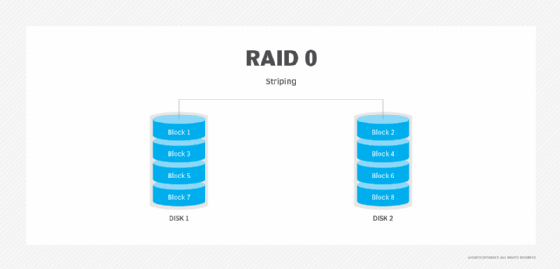
RAID 0: RAID 0 is called disk striping. All the data is spread out in chunks across all the disks in the RAID set. RAID 0 has great performance because you spread the load of storing data onto more physical drives. There is no parity generated for RAID 0. Therefore, there is no overhead to write data to RAID 0 disks.
RAID 0 is only good for better performance, and not for high availability, since parity is not generated for RAID 0 disks. RAID 0 requires at least two physical disks.
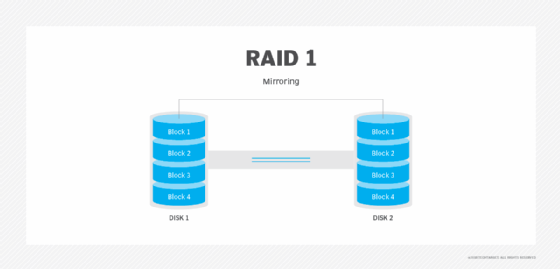
RAID 1: In RAID 1, also called disk mirroring, all the data is written to at least two separate physical disks. The disks are essentially mirror images of each other. If one disk fails, the other can be used to retrieve data.
Disk mirroring is good for very fast read operations. It's slower when writing to the disks, since the data needs to be written twice. RAID 1 requires at least two physical disks.
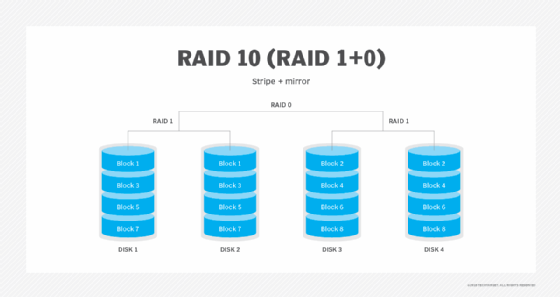
RAID 1+0: RAID 1+0, which is also called RAID 10, uses a combination of disk mirroring and disk striping. The data is normally mirrored first, and then striped. Mirroring striped sets accomplishes the same task, but is less fault-tolerant than striping mirror sets.
If you lose a drive in a stripe set, all access to data must be from the other stripe set because stripe sets have no parity. RAID 1+0 requires a minimum of four physical disks.
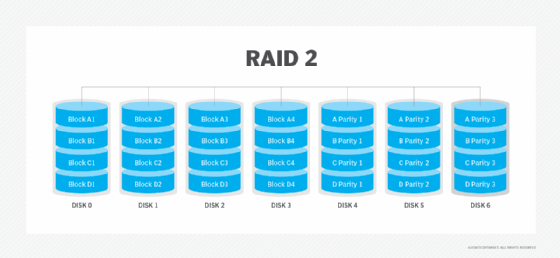
RAID 2: Using a Hamming code, RAID 2stripes data at the bit level. These days, Hamming codes are already used in the error correction codes of hard drives, so RAID 2 is no longer used.
RAID 3: RAID 3 uses something called a parity disk to store the parity information generated by the RAID controller on a separate disk from the actual data disks, instead of striping it with the data, as in RAID 5.
This RAID type performs poorly when there are a lot of requests for data, as in an application such as a database. RAID 3 performs well with applications that require one long sequential data transfer, such as video servers. RAID 3 requires a minimum of three physical disks.
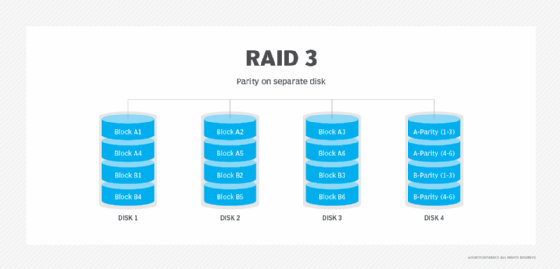
RAID 4: RAID 4 uses a dedicated parity disk, as well as block-level striping across disks. While it is good for sequential data access, the use of a dedicated parity disk can cause performance bottlenecks for write operations. With alternatives such as RAID 5 available, RAID 4 is not used much.
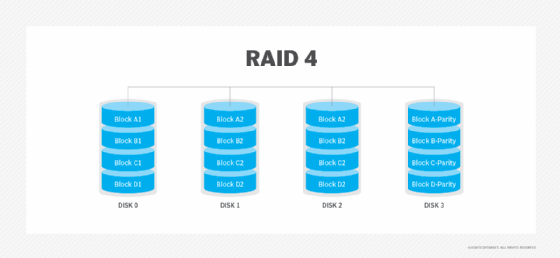
RAID 5: RAID 5 uses disk striping with parity. The data is striped across all the disks in the RAID set, along with the parity information needed to reconstruct the data in case of disk failure.
RAID 5 is the most common method used because it achieves a good balance between performance and availability. RAID 5 requires at least three physical disks.
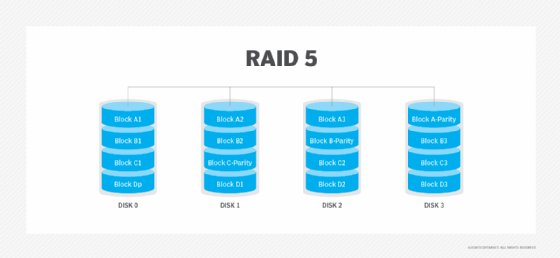
RAID 6: RAID 6 increases reliability by utilizing two parity stripes, which allow for two disk failures within the RAID set before data is lost. RAID 6 is seen in SATA environments, and solutions that require long data retention periods, such as data archiving or disk-based backup.
Adaptive RAID: Adaptive RAID lets the RAID controller figure out how to store the parity on the disks. It chooses between RAID 3 and RAID 5, depending on which RAID set type will perform better with the type of data being written to the disks.
RAID 7: RAID 7 is a nonstandard RAID level -- based on RAID 3 and RAID 4 -- that requires proprietary hardware. This RAID level is owned and trademarked by the now-defunct Storage Computer Corp.
Minimum drives and rebuilds for RAID levels
Regarding the question about the benefit of using more disks in a RAID set than the minimum, the answer is that you get more available storage and more actuators or spindles for the OS to use.
Most RAID arrays use a maximum of 16 drives within a RAID set due to higher overhead and diminishing returns in performance when exceeding that many drives. Up to eight drives seems to be a good rule of thumb for RAID 5 and RAID 10. If you need more space, you can create another RAID set with the other disks.
As another rule of thumb, try to keep different workload data types on separate RAID sets. You can use RAID 10 for best performance everywhere, but most budgets dictate the use of RAID 5 for database data volumes, with RAID 1 or RAID 10 used on database log volumes. The database volumes can be highly random I/O, and the logs tend to be sequential in nature.
Rebuild times depend on the kind of RAID. If you are using software-based RAID, then more spindles within the group means longer rebuild times. If it's hardware-based RAID, rebuild times are usually dictated by the size of the drives themselves, since the hardware usually does the sparing in and out of the set. A 146 GB drive takes longer to rebuild than a 73 GB drive.
How RAID is used today
Many experts say the need for RAID technology has shrunk. Erasure coding and solid-state drives have presented reliable -- if more expensive -- alternatives, and as storage capacity increases, the chance of RAID array errors increases, as well.
Erin Sullivan and Christopher Poelker asks:
Are you still using RAID in your storage environment or have you implemented erasure coding?
However, if RAID is dead, there are some major storage vendors that have not gotten the memo. Dell EMC recently released the Unity platform, which supports multiple RAID levels, and IBM and Intel have also released products that support and boost RAID performance.
Next Steps
Can RAID technology benefit object storage?
Supplement RAID with storage virtualization
How data growth affects the RAID and erasure coding battle
This was last published in October 2017
Related Resources
Performance Expectations of Hybrid Cloud NAS–PanzuraA Buyer's Guide to Hybrid Cloud NAS–PanzuraThink you have a NAS solution? Think Again–IBMWhy NAS File Migrations Don't Have to Be a Nightmare Anymore–Data DynamicsVIEW MORE
Dig Deeper on NAS devices
ALLNEWSGET STARTEDEVALUATEMANAGEPROBLEM SOLVE
Qumulo storage parts the clouds with its K-Series active archive
network-attached storage (NAS)
Server maker IXsystems sets sail with new TrueNAS flagship
Qumulo P-Series packs NVMe into scale-out NAS
Load More
Join the conversation
Send me notifications when other members comment.Add My Comment
Michael Tidmarsh- 22 Sep 2014 1:07 PM
Even though I do think that erasure coding does offer better data protection, it's too costly so I'll stick with RAID
SANdummy- 10 Nov 2014 7:00 PM
Are you still using RAID in your storage environment or have you implemented erasure coding?
VasudevanSanjeevee- 10 Sep 2016 6:16 AM
i need to refer top to bottom of RAID in VMware environment ..What to do ?
Surferboy- 10 Dec 2017 8:11 AM
I have no idea how a RAID is configured. So, can I have a 4 bay NAS and insert one drive into the later, insert another drive of the same size. Then later again insert two more drives of a different size and end up with a RAID 5 system.
Comments
Post a Comment